Tutorial
In this short tutorial we will describe how you can use the 3D-GNOME web server and demonstrate the sample results.
Suppose that we are interested in a 35045500-35704867 region of chromosome 14. To start go to the Run analysis page. There is a number of options available there, but it is enough to provide the genomic region of interest. Enter the value "chr14:35045500-35704867" in the Region to reconstruct field and click the Send request button below. A notification of successful request submission should appear at the top of the page together with a link to the results page. You will find there a graph showing chromatin interactions in the submitted region, a 3D model of this region and other graphs and statistics describing the spatial structure of the region of interest (the results are described below in more detail).
While the 3D-GNOME webserver has employed a simulated annealing Monte Carlo approach in its modeling engine from its first version, starting with version 3.0, it gained the ability to generate ensembles of models. In the field number of models in ensemble specify how many models you want to generate (maximum is 100). This allows for the creation of multiple models with different conformations for the same region, providing a better representation of the region's variability.
Apart from building 3D models of selected genomic regions directly from chromatin interaction data, the 3D-GNOME is capable of modeling genomic regions which differ from the reference sample by a set of structural variants (SVs) like: deletions, duplications, inversions or insertions. To model a structure of a genomic segment in a human lymphoblastoid cell with identified SVs enter on the Run analysis page the list of these SVs along with the region specification. There are several ways through which you can submit the list of SVs to the server. Click the Select button next to the Structure Variants field on the Run analysis page and a list of all the input options will unroll:
- Upload VCF file - upload a file with SVs in .vcf format from your computer. In the field named sample ID provided under the Browse button you can put ID of only this sample present in the uploaded file for which you want to get models.
- Select sample ID - select ID of the samples of interest from the 1000 Genomes Project (1kGP) phase 3 extended by 30x high-coverage data from the NYGC 3,202 (samples). After you provide the ID, all the SVs identified in the 1kGP for the selected samples will be extracted from the 1kGP database and models for reference and both allelic variants will be computed.
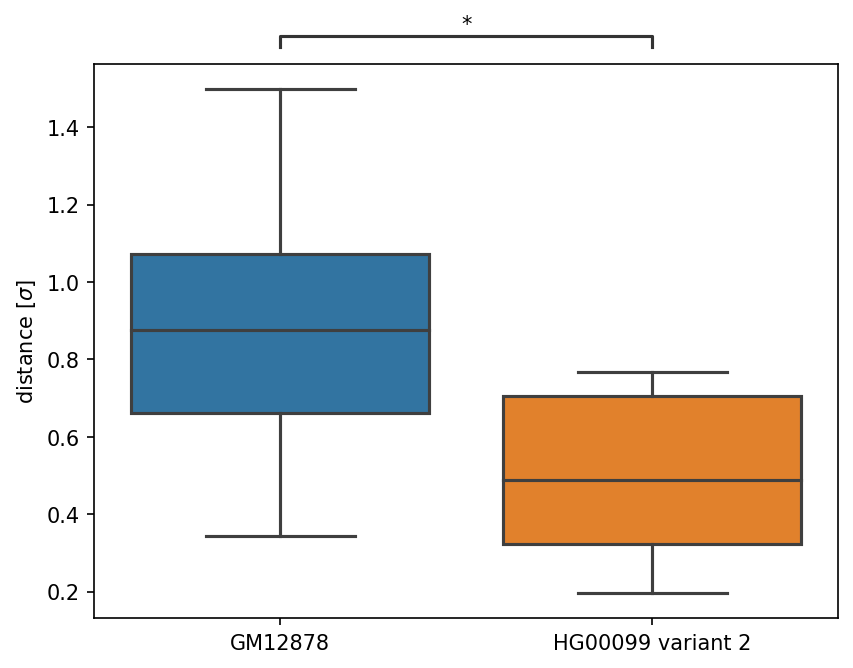
In 3D-GNOME 3.0, we added the ability to analyse changes in spatial distances between gene promoters and enhancers caused by structural variants. To perform this analysis, upload a .vcf file with SVs or select an ID from the 1kGP list and specify the number of models in the ensemble field. The minimum number of models for ensemble analysis is 10. During simulation, 3D-GNOME generates an ensemble of models. Genes (GENCODE HG38) and enhancers (Enhancer Atlas 2.0, liftovered to HG38) are mapped onto each model, and the Euclidean distance between enhancers is calculated. The distance measure is specific to the 3D-GNOME engine, so the key factor for analysis is a change in distance distribution, as demonstrated in Sadowski et al.. To test the significance of the change in distance distribution, we use the Mann-Whitney U test with a p-value threshold of 0.05. It should be noticed that only the genes and enhancers located in the 3D model in different beads (one bead equals 1kb bp) are considered in this analysis. Additionally, only those genes and enhancers that are not directly affected by SVs (i.e. deletion of the gene or enhancer makes it impossible to calculate distance distribution in variants) are included After you are done with specification of genomic region and SVs, click Send request button.
The computations time based on the region size, Structure Variation and Ensemble analysis - it can take several seconds, but it may take up to several hours. You are strongly advised to save the address to be able to access the results later.
If you would follow the link and go to the results page before the computations are done you will see the current status of the request (Received means that the request was sent, Started means that the processing of the request was started). Should there be any errors in your request they will also be shown on this page.
The page with results contains interaction plots, heatmaps and plots presenting statistics. On the left there is a control panel, where you can select, which elements exactly you want to be visible (tick these which are of your interest).

Interaction plot is a graphical representation of the clusters contained in the specified region (Fig 1). Every interaction is represented with an arc of the height corresponding to the interaction frequency. 3D-GNOME visualise chromatin interactions, and genomic annotations: SVs, enhancers and genes, using IGV genomic browser.





In the left margin of the page with results links to 3D viewer are listed. Users can click the link which will present the structure modified by SVs next to the reference structure or solely the former one. The 3D viewer will open in a new page. When you arrive at the page you should see a 3D model (or two in case of the comparison of the reference and variant structure) (Fig. 3), with mapped genes (red) and enhancers (yellow) mapped on the structures. Only one model from the ensemble is visualise - rest of it you can find in a download section on main result web page. For visualisation we use NGL

Table with basic statistics (Fig. 4) contains:
- Number of interactions - total number of interactions of a given type
- Minimal length - length of the shortest interaction
- Maximal length - length of the longest interaction
- Average length - average length of the interaction
- Maximal count - the frequency of the most frequent interaction
Please note that by clicking on "singletons" or "clusters" you can download a file with a list of the corresponding interactions.
Interestingly, we can see the most frequent interaction is a singleton and not a PET cluster (248 vs. 238). This may seem a bit misleading at first - please see FAQ for an explanation.

Heatmaps of singleton interactions. Because of the huge number of singletons they are presented in an aggregated form of a heatmap (Fig 5). In a raw heatmap each cell represents the number of interactions between the two corresponding genomic regions. As these numbers are biased (for example by a local region visibility), we normalize all the entries using a simple matrix balancing algorithm called Vanilla-Coverage normalization (for a discussion of different heatmap normalizations see [Rao et al, 2015]).
Heatmaps are useful for identification of contact domains (TADs). In our case we can see that there are 4 visible domains, with the first 3 forming something like a higher-hierarchy domain. This hierarchical nature of domains is something that is very often observed in the data, but there is still no consensus about how to treat them, and depending on your needs you may want to take a look at the individual domains or at the bigger, aggregated ones. Please note that you can click the "Heatmap" links to download the file with numerical representation of the heatmaps.
 >
>
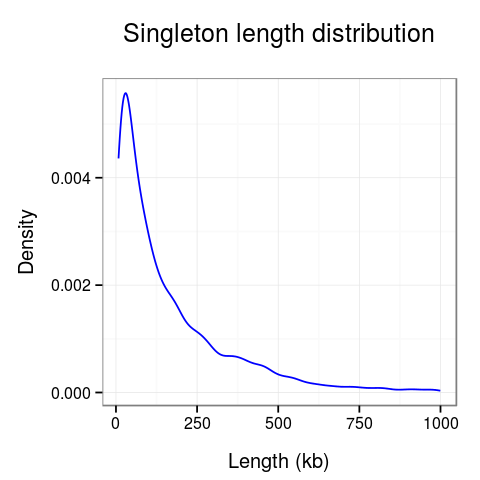
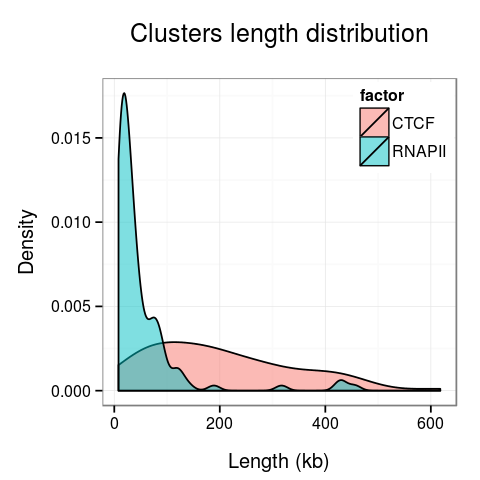
Plots presenting statistics. There are 2 plots showing the distribution of lengths of clusters and singletons (Fig. 6). Based on these plots the density, or looping of the analyzed region can be estimated. For example, a large number of short clusters means that there is a large number of short chromatin loops in the region. We can also study differences between interactions mediated by different transcription factors - here we see that RNAPII forms significantly shorter loops than CTCF does, although there are some longer loops, up to 400kb. Note that for clarity the singleton plot is capped to 1Mb, and the cluster one - to 600kb.

On the last plot (Fig. 7) we can see the distribution of the interactions across the region.
The 10-10.5Mb region seems to have significantly fewer interactions than other regions. Surprisingly, there is also much fewer interactions at the 10.7Mb loci.
The download section includes the entire generated ensemble of models in mmCIF and XYZ format for manual analysis using i.e. UCSC Chimera . Additionally, a tsv file with the results of the distance analysis is provided, including gene IDs, gene and enhancer coordinates, average distances in the ensemble, and the results of the Mann-Whitney U test of distribution changes (p-value and statistical value). Each gene-enhancer distance boxplot generated by clicking the "Generate boxplots" button is also included in the output file folder.